Picard Sidekiq Tip: Split Up Independant Operations
December 20, 2023 📬 Get My Weekly Newsletter ☞
A while back, Joe Sondow posted a great thread on Mastodon that is a perfect example of why you should split a complex job up into several individual ones. Basically, Worf was experiencing an error that caused Riker to post more than he should have.
A big theme of my Sidekiq book is to handle failure by making jobs idempotent—allowing them to be safely retried on failure, but only having a single effect.
While Joe is not using Sidekiq, the same theories apply. His job’s logic is basically like so:
- Picard Tips executes
- Then, Riker Googling runs
- After that, Worf Email does its thing
- Last but not least, Locutus Tips posts.
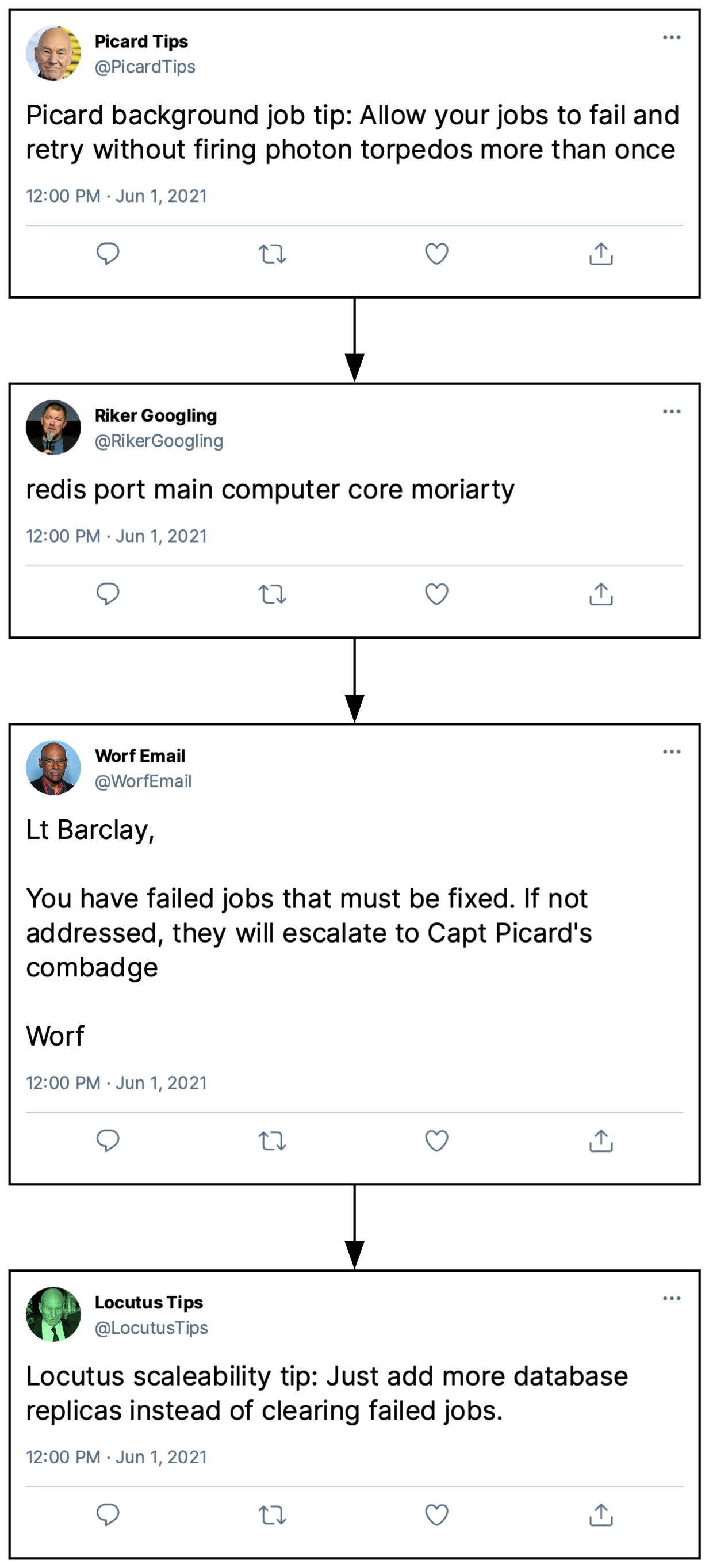
Ideally, if Worf’s email fails, it should get retried until Worf succeeds. It should not cause Riker to google more or for Picard to present additional tips. And it shouldn’t prevent Locutus from sharing his wisdom, either.
For Joe’s Lambda function, this isn’t how it worked, unfortunately. Worf had an issue and while Picard was able to avoid posting more than once, Riker was not.
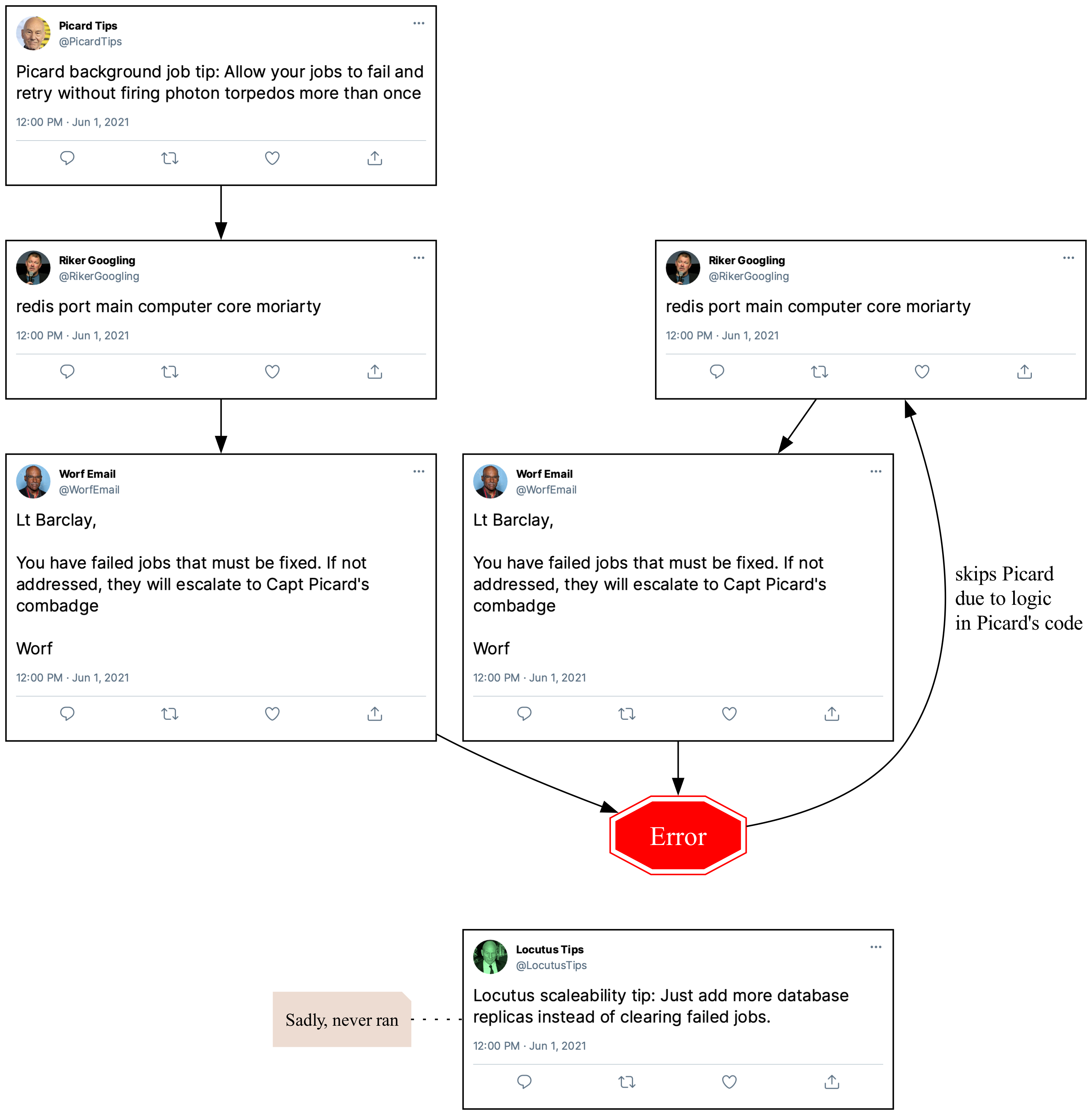
Joe’s solution—which he admits isn’t great—is to catch all errors and exit the entire process when one is caught.
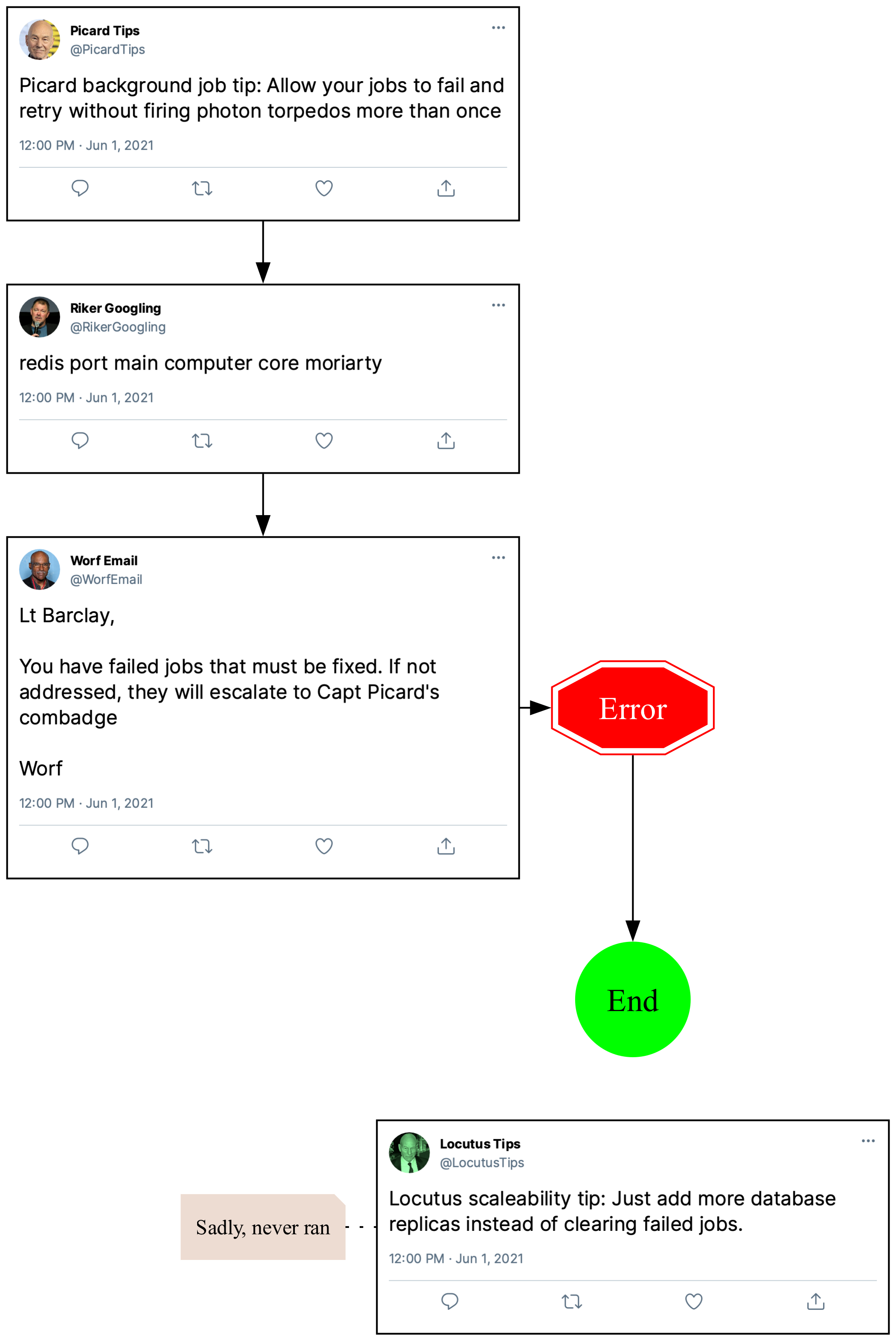
This is actually not that bad of a strategy! In Joe’s case, the bots will run the next day and if the underlying problem was transient, everyone will be fine. They’ll miss one day hearing about how Locutus thinks you should run your life, but it’s fine.
If these jobs were more important, the way to make the entire operation idempotent is to create five jobs:
You’d have one top-level job that queues the others:
class BotsJob
include Sidekiq::Job
def perform
PicardJob.perform_async
RikerJob.perform_async
WorfJob.perform_async
LocutusJob.perform_async
end
end
Each of those jobs would then have logic that it sounds like Picard Tips already has: don’t post if you’ve already posted. But, this time, if any of the jobs fail, it won’t affect the other jobs.
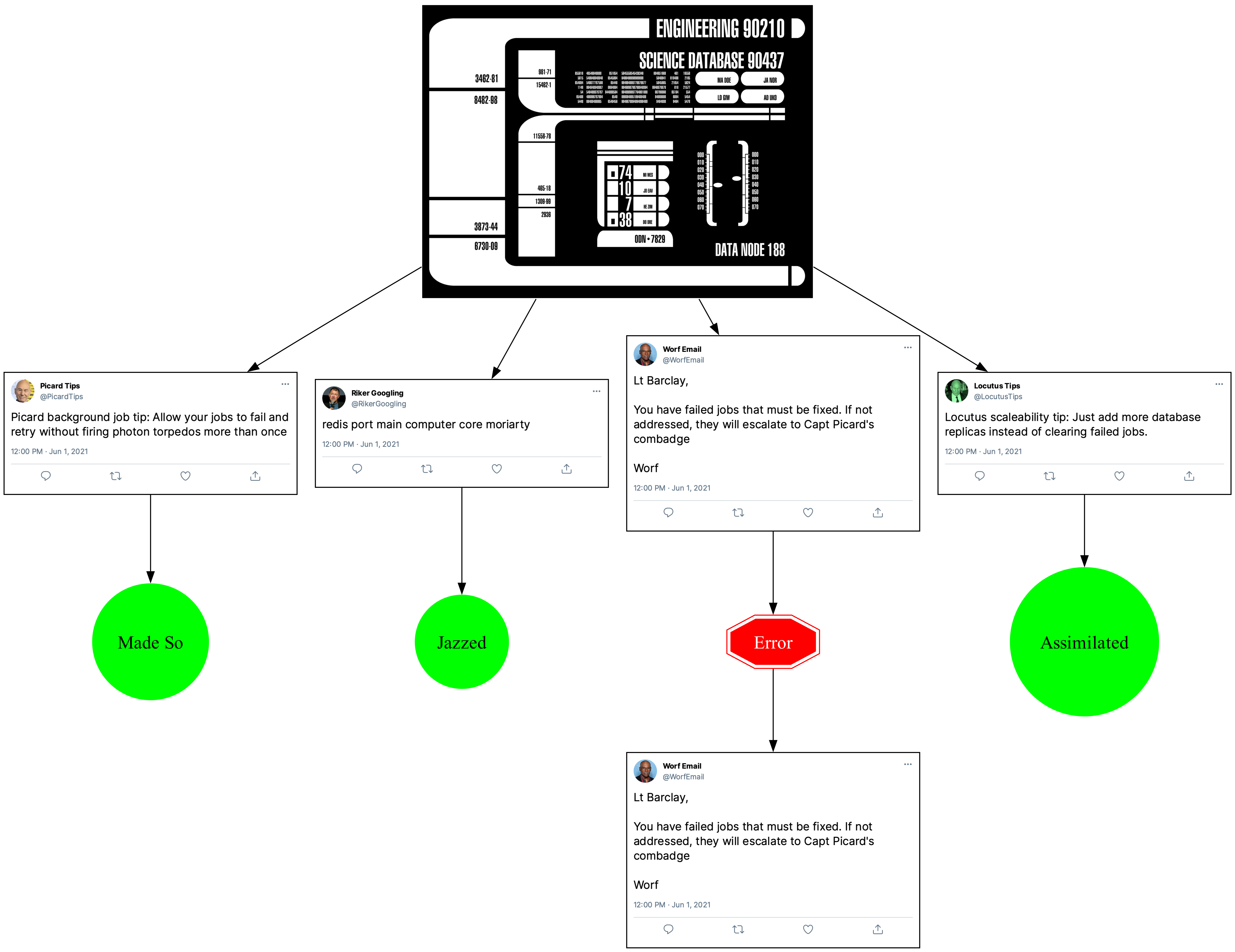
The only problem with the Ruby code for this is that we can’t call PicardJob.make_it_so!